Sample scripts are provided as-is with no warranty of fitness for a particular purpose. These scripts are solely intended to demonstrate techniques for accomplishing common tasks. Additional script logic and error-handling may need to be added to achieve the desired results in your specific environment.
parse_html_directory.s
This sample was designed for Robo-FTP 3.8. Although built-in support for the default Apache directory listing format was added in Robo-FTP 3.9, this sample is still useful as a tutorial for writing a custom directory parsing script.
There is more than one type of HTTP server and there is no official standard method to request a directory listing from an HTTP server. Some HTTP servers are designed specifically for file transfer so they return machine-readable directory listings. The ability to interface with this type of server is built into Robo-FTP.
Meanwhile, web servers are HTTP servers designed to serve web pages to web browsers. Some web servers will provide a directory listing when you make a GET request on the URL of a folder. There is no standard format for this type of listing. It is usually HTML designed to be displayed as a web page that is readable to humans.
Robo-FTP script commands may be used to parse an HTML web page and perform some action based on the contents. In this example we'll parse a web page that represents a directory listing and download all of the files. The page looks like this in a browser:
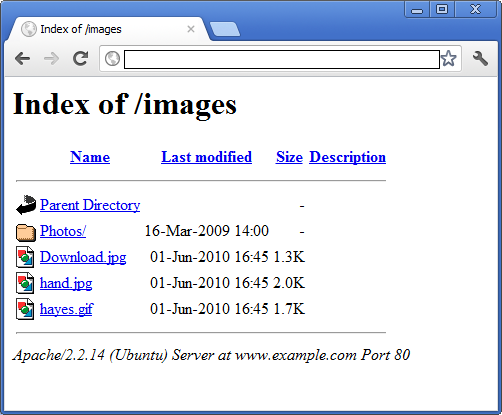
The directory listing displayed above is actually an HTML page rather than a machine-readable listing.
If you view the source of the listing above you'll see this:
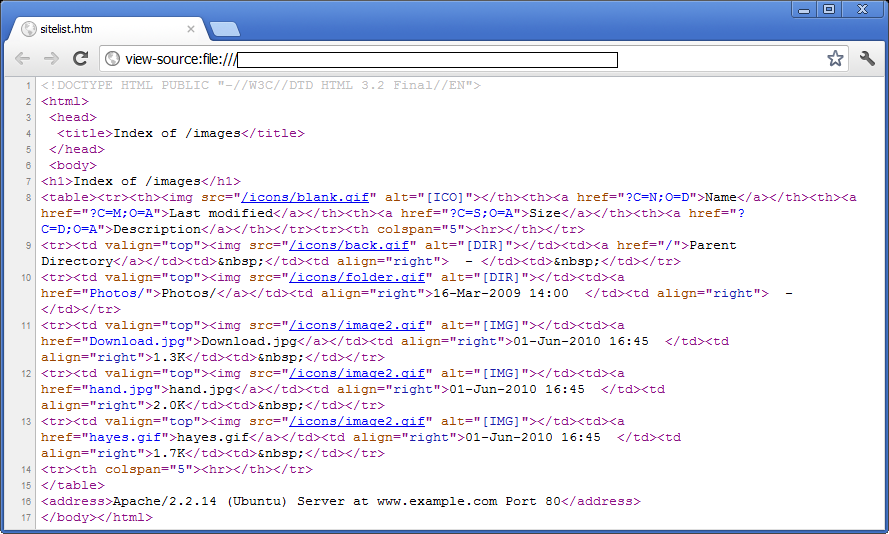
In this directory listing, each file appears on its own line in an html anchor tag that looks like this: <a href="file.txt">file.txt</a>. Folders appear on their own lines in the same format, but with a trailing slash like this: <a href="folder/">folder/</a>.
This script uses the FTPLIST command to retrieve the directory listing. It then uses READFILE to look at each line of the directory listing. SETSUBSTR, SETEXTRACT, and IFSTRCMP are used to find all the chunks of text that match the format referenced above, retrieve the file name (making sure we have found a file and not a folder), and download the file.
The point of this sample is to show you how to design a Robo-FTP script that parses a web page. The code below is very specific to this particular page and would need to be substantially modified to parse a different page. Writing this type of custom script can be challenging so you may wish to hire our Professional Services team on time-sensitive projects.
Note: The DISPLAY command is very helpful when testing a Robo-FTP script that parses text files.
1 ;; connect and change directory into source folder
2 FTPLOGON 'www.example.com' /servertype=HTTP
3 FTPCD "images"
4
5 ;; get HTML listing into sitelist.txt
6 FTPLIST
7 IFERROR GOTO done
8
9 ;; reset the file pointer by calling READFILE with no arguments
10 READFILE
11
12 :loop
13 READFILE 'sitelist.txt' row /record=next
14 IFERROR GOTO done
15 ;; How many times does href=" appear on this line?
16 SETSUBSTR chunks = row 'href="'
17 IFNUM!= chunks 1 GOTO loop
18
19 ;; Get filename out of the second half of the line
20 SETEXTRACT chunk = row 'href="' 2
21 SETEXTRACT url = chunk '"' 1
22
23 ;; Don't download if last character is slash (folder not file)
24 SETRIGHT last = url 1
25 IFSTRCMP last '/' GOTO loop
26
27 ;; Download now
28 RCVFILE url
29 GOTO loop
30
31 :done
32 FTPLOGOFF
33 DELETE 'sitelist.txt'